With the Northern Hemisphere arrival of summer it’s swing camp season and that means one thing – completely out of sync with the rest of the population it’s swing flu season. And with the swing flu season comes all sorts of remedies to ward off the lergy from Herräng’s anti-cold juice to bottles of military-grade Nyquil. But does any of this actually work?
How Many Lindy Hoppers are There
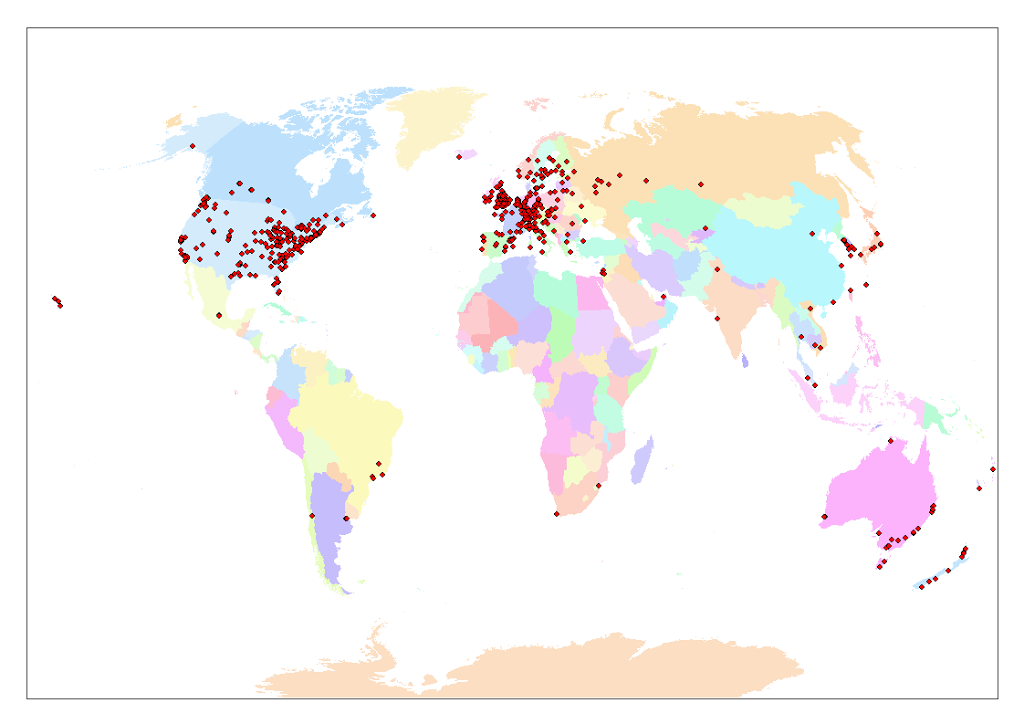
I’ve been wondering about this question for a while but with a little free time I finally got around to having a decent crack at working it out with some GIS and statistics.The short answer: by my estimation about 120,000. Read on for the longer answer. Where are people Lindy Hopping? This is actually a
Who’s on first? Performance order and judging bias in Lindy Hop contests

Making decisions is hard. Judging in contests is a hard form of decision making – there’s so much to consider. What’s worse is that your own brain will try and prevent you from making the best decision. For example every time someone has to decide on information being presented to them, the order of the
What is the new ‘Middle Class’?
The post-budget articles in the newspapers are making me sick. Making out families on $150,000 a year as though they’re on struggle street is pretty dirty, when folk in that situation are better off than most of us. Matt Cowgill has written an excellent piece trying to find out what the middle class (middle meaning
The Canadian Election: Why they need preferential voting
I like Canada and I like elections (it’s my largest tag word at the moment, which I should really do something about). Canada had an election a couple of days ago hence I shall discuss. For a country considered fairly liberal the political system is somewhat backward. The Senate is not elected (and there have
NSW State Election Contests: The Swing
This is the final in my series of NSW State Election Contests posts, previewing the interesting contests for election watchers beyond the obvious conclusion of the poll. I’ll be back after March 26 to make more commentary. In this post I’ll examine the swing. What is the swing?For those Lindy Hoppers out there I’m not
Working Families?
With a state election in NSW in the next few weeks and a federal election one by-election away we’re again being bombarded with political commercials. Here’s a few for sampling: NSW Labor’s “Fairness for Families” NSW Liberal’s spoof of the above (which gets points for comedy) And (because it features Zombies) my favourite
Blogroll
- Dogpossum.org
omg just park that hire bike PROPERLY. Or yet another reason to hate Chris Minns - J.S.Almonte - Wandering and Pondering
Speaking Strictly Lindy Hop - Mazz Jazz
DaD: cosa stiamo facendo? - My Jazz Can Beat Up Your Jazz
- Shuffle Projects
Alphabetical Jazz Steps – Edition 3 (2017) with Chester Whitmore - Swungover
“Midge” — A New York Lindy Hop Story
Copyright © 2026 Lindypenguin |